シーオーリポーツ for Java V3の『ページごとにファイルを分割する』機能
製品開発担当の大です。こんにちは。
前回に引き続き、シーオーリポーツ for Java V3の新機能をご紹介します。
今回は、ページごとにファイルを分割する機能です。
ページごとにファイルを分割する
ページごとにファイルを分割する
従来TIFF出力時にだけ指定できていたMultiPageプロパティが、他のドキュメント形式でも使用できるようになりました。また、ファイル分割する場合のファイル名を柔軟に指定できるようになりました。
以下に例をあげます。このような給与明細のCSVデータがあったとします。
| 社員番号 | 氏名 | 差引支給額 | (その他の項目は今回は省略) |
|---|---|---|---|
| 1001 | 佐々木 カナ | 500000 | |
| 1002 | 宗谷 ホマレ | 400000 | |
| 1003 | 旭川 ピリカ | 300000 | |
| 1004 | 工藤 ヒロユキ | 200000 |
このデータの1行を1つのPDFファイルにしたいと考えたとき、従来はジョブをそれぞれの行で作り直す必要があり、大変手間がかかりました。
シーオーリポーツ for Java V3では、以下のように簡単に書くことができます。
var job = new CrFileOutJob(CorDocumentType.PDF);
job.setMultiPage(false);
job.setFileNameGenerator(() -> data.get("社員番号") + " " + data.get("氏名"));
MultiPageはデフォルトでtrueですが、falseにすることにより、1ページごとにファイルを作り直します。
ファイル名は、従来どおりjob.setFileName("ファイル名")とした場合はファイル名の後ろに括弧つきのページ番号が入り『ファイル名(1).pdf』となります。上記のようにFileNameGeneratorを指定することもできます。
サンプルコードの全体は以下のようになります。
public class 給与明細サンプル {
public static void main(String[] args) throws Exception {
var data = new 給与明細データ();
var draw = new CrDraw();
try {
var job = new CrFileOutJob(CorDocumentType.PDF);
job.setMultiPage(false);
job.setFileNameGenerator(() -> data.get("社員番号") + " " + data.get("氏名"));
job.start(draw);
try (var form = CrForm.open(draw, "給与明細.rse")) {
do {
form.getField("差引支給額").setData(data.get("差引支給額"));
// (その他の項目は今回は省略)
form.printOut();
} while (data.next());
} catch (Exception ex) {
job.abort();
throw ex;
}
job.end();
} finally {
draw.deleteInstance();
}
}
}
class 給与明細データ {
List<Map<String, String>> list;
int index = 0;
// ここではCSV読み込みのためJacksonライブラリを使用しています
// https://github.com/FasterXML/jackson-dataformats-text/tree/master/csv
給与明細データ() throws JsonProcessingException, IOException {
var file = new File("給与明細.csv");
var schema = CsvSchema.emptySchema().withHeader();
var reader = new CsvMapper().readerFor(Map.class).with(schema);
try (var it = reader.<Map<String, String>>readValues(file)) {
list = it.readAll();
}
}
String get(String key) {
return list.get(index).get(key);
}
boolean next() {
return ++index < list.size();
}
}
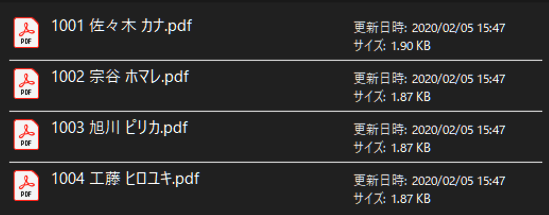
出力結果:
ページごとにファイルを分割する
ページごとに指定したファイル名で出力されましたね!
体験版が無料でダウンロードできますので、ぜひお試しください。
