シーオーリポーツドキュメントからテキストデータを抽出してCSVとして保存する
製品開発担当の大です。こんにちは。暖かくなってきましたね。
さて、今日はシーオーリポーツのドキュメント形式の話をしたいと思います。
シーオーリポーツのドキュメント形式は3種類あります。
- RSI(バイナリ形式)
- RSX(XML形式)
- CID(旧バイナリ形式。ActiveX版製品のみ対応している)
このうち、RSXについては仕様が公開されており、加工や再利用がしやすくなっています。
RSIとRSXはフォーマットが違うだけで表現できる帳票は同じですので、再利用する可能性がある場合はRSXで、そうでない場合はサイズの小さくなるRSIで、という風に使い分けると良いでしょう。
今回はこの再利用の例として、「ドキュメントからテキストデータを抽出してCSVとして保存する」ということをやってみたいと思います。
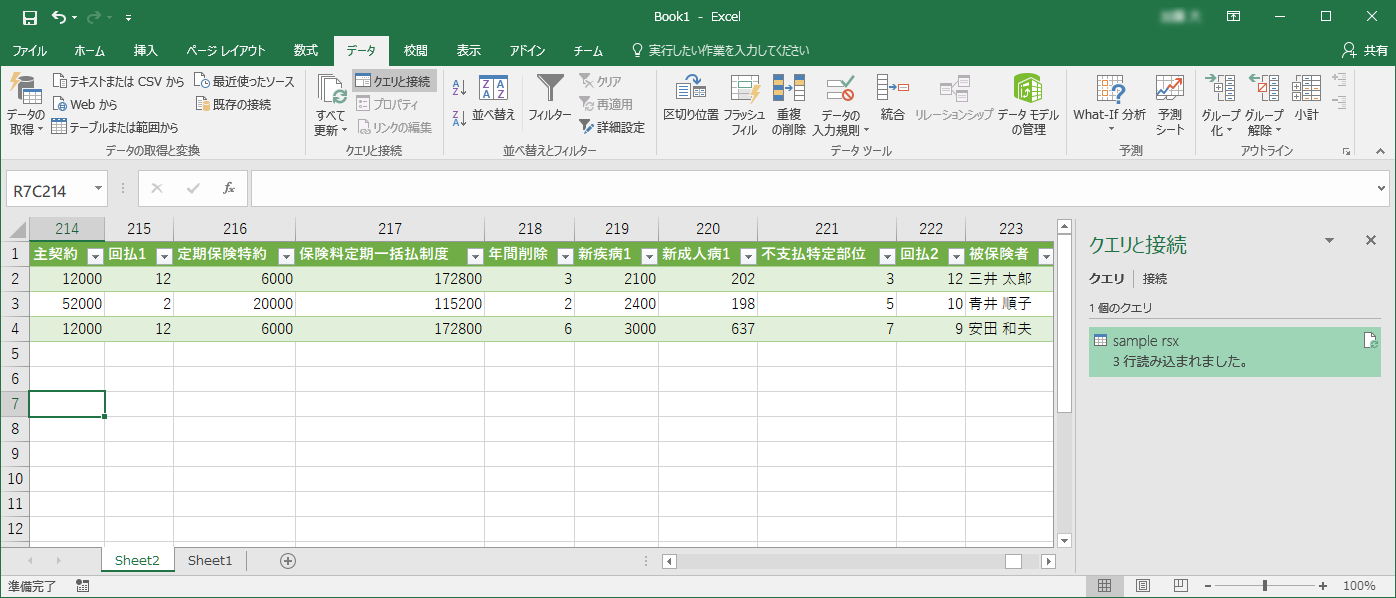
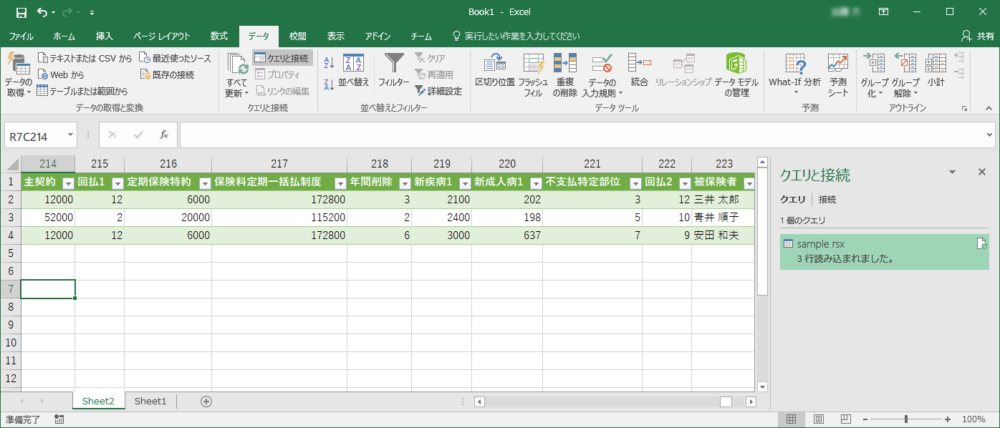
ドキュメントから抽出したテキストデータのCSV(クリックで拡大)
RSX形式のドキュメント
RSX形式のドキュメントは、おおざっぱに描くとこんな感じの構成になっています。

RSXの構成(クリックで拡大)
ドキュメントの本文は「ページ」にあります。ページは、フォームエディタで作成した「フォーム」(レイアウトの情報)、そのフォームに対するデータの設定等の更新情報、さらに動的に描画されたオブジェクトの情報で構成されています。今回は、CSVの項目名を「フォーム」から抽出し、CSVの1行が各ページから抽出したテキストデータになるようにしてみます。
RSXは前述のとおりXMLのドキュメントですので、一般的なXMLパーサで読み込むことが可能です。
シーオーリポーツ製品のインストールフォルダにRsxSchemaというフォルダがあり、スキーマファイルと補足資料がありますので、詳細はこちらをご覧ください(お使いの製品が古い場合は無いかもしれません……。その場合は最新のリビジョンに更新してください)。
ソース
Javaで書いてみました。コンパイルにはJava8以上が必要です。
RSXtoCSV.java
public class RSXtoCSV {
public static void main(String[] args) throws Exception {
if (args.length == 0) {
System.out.println("Usage: java RSXtoCSV <RSXのパス> [<CSVのパス>]");
return;
}
Path rsx = Paths.get(args[0]);
Path csv;
if (args.length == 1) {
// CSVのパスが指定されていなければRSXと同じパスに拡張子.csvを追加して保存します
csv = Paths.get(args[0] + ".csv");
} else {
csv = Paths.get(args[1]);
}
try (InputStream is = Files.newInputStream(rsx);
Writer writer = Files.newBufferedWriter(csv)) {
// Excelで読み込みやすいようにBOM付きUTF-8で出力します
writer.write("\ufeff");
writer.write(new RSXParser(is).extractText());
}
System.out.println("正常出力: " + csv.toAbsolutePath());
}
}
class RSXParser {
private XPath xpath = XPathFactory.newInstance().newXPath();
private Document document;
RSXParser(InputStream is) throws SAXException, IOException, ParserConfigurationException {
document = DocumentBuilderFactory.newInstance().newDocumentBuilder().parse(is);
}
// テキストを抽出してCSVとして取得します
String extractText() {
CSV csv = new CSV();
List<Node> forms = getNodes("//CoReportsForm", document);
boolean multipleForms = forms.size() > 1;
forms.forEach(form -> extractFormData(form, csv, multipleForms));
List<Node> pages = getNodes("//Page", document);
pages.forEach(page -> extractPageData(page, csv, multipleForms));
return csv.toString();
}
// フォームのデータを抽出してCSVのヘッダとテンプレート行を作成します
private void extractFormData(Node form, CSV csv, boolean multipleForms) {
// フォームが複数あるなら項目名を一意にするためフォーム番号をプレフィックスとして使用する
String prefix = multipleForms ? getString("../@No", form) + "_" : "";
// ラベル
getNodes(".//Label", form).forEach(label -> {
csv.newColumn(prefix + getString("@Name", label), getString("Text", label));
});
// データフィールドとテキストフィールド
getNodes(".//TextField|.//DataField", form).forEach(field -> {
csv.newColumn(prefix + getString("@Name", field), "");
});
// リストフィールド
getNodes(".//ListField", form).forEach(list -> {
String listName = getString("@Name", list);
int columns = getInt("Columns", list);
int rows = getInt("Rows", list);
csv.newColumn(prefix + listName, "");
IntStream.rangeClosed(1, columns).forEach(c -> {
IntStream.rangeClosed(1, rows).forEach(r -> {
csv.newColumn(prefix + listName + " (" + c + "," + r + ")", "");
});
});
});
}
// ページデータを抽出してCSVの行を作成します
private void extractPageData(Node page, CSV csv, boolean multipleForms) {
// 1ページのデータ = CSVの1行とします
csv.next();
// フォームが複数あるならフォーム番号を取得
// No属性がある場合はそこに、ない場合はForm直下のテキストに入っています
String prefix = multipleForms ? getString("Form/@No|Form[not(@No)]", page) + "_" : "";
// オブジェクトの更新データにテキストが含まれるものを取得します
getNodes("UpdateObject[Text]", page).forEach(obj -> {
String name = getString("@Name", obj);
String r = getString("@Row", obj);
String c = getString("@Column", obj);
String columnName = prefix + name;
if (!r.isEmpty() && !c.isEmpty()) {
columnName += " (" + c + "," + r + ")";
}
csv.putIfPresent(columnName, () -> getString("Text", obj));
});
// 動的描画オブジェクトはラベルオブジェクトのみ追加します
getNodes("AddObjects/Label", page).forEach(label -> {
csv.add(getString("Text", label));
});
}
// ラムダ式内で使いやすくするためXPathExpressionExceptionをRuntimeExceptionでラップしときます
private Object evaluate(String expression, Node item, QName returnType) {
try {
return xpath.evaluate(expression, item, returnType);
} catch (XPathExpressionException ex) {
throw new RuntimeException(ex);
}
}
// NODESETで返されるNodeListは扱いづらいのでList<Node>に詰め替えます
private List<Node> getNodes(String expression, Node item) {
NodeList nodes = (NodeList) evaluate(expression, item, XPathConstants.NODESET);
List<Node> list = new ArrayList<>();
IntStream.range(0, nodes.getLength()).forEach(i -> list.add(nodes.item(i)));
return list;
}
// NUMBERはDoubleで返されてしまうのでintが欲しいときはこれを使います
private int getInt(String expression, Node item) {
return ((Double) evaluate(expression, item, XPathConstants.NUMBER)).intValue();
}
// ついでに文字列取得も他にあわせて用意しときます
private String getString(String expression, Node item) {
return (String) evaluate(expression, item, XPathConstants.STRING);
}
}
class CSV {
private List<String> header = new ArrayList<>();
private List<String> templateRow = new ArrayList<>();
private List<String> currentRow = null;
private List<List<String>> rows = new ArrayList<>();
// カラムを追加します
void newColumn(String columnName, String initialValue) {
header.add(columnName);
templateRow.add(initialValue);
}
// 現在行の最後に値を追加します
void add(String value) {
currentRow.add(value);
}
// 項目名がヘッダに存在していたら値を現在行のそのインデックスに追加します
void putIfPresent(String columnName, Supplier<String> supplier) {
int index = header.indexOf(columnName);
if (index >= 0) {
currentRow.set(index, supplier.get());
}
}
// 行を次に進めます
void next() {
currentRow = new ArrayList<>(templateRow);
rows.add(currentRow);
}
// 文字列のリストをCSVの1行に変換します
private String listToCSVString(List<String> list) {
return list.stream().map(s -> s.replace("\"", "\"\""))
.collect(Collectors.joining("\",\"", "\"", "\"\n"));
}
@Override
public String toString() {
// カラム数が一番大きい行に合わせてヘッダのカラム数を拡張します
List<String> max = Collections.max(rows, Comparator.comparing(List::size));
IntStream.range(0, max.size() - header.size()).forEach(i -> header.add("動的描画" + i));
// ヘッダとデータ行を書き出します
StringBuilder sb = new StringBuilder();
sb.append(listToCSVString(header));
rows.forEach(row -> sb.append(listToCSVString(row)));
return sb.toString();
}
}
実行
引数でrsxのパスを渡して実行します。
$ java -cp bin RSXtoCSV c:\tekito\sample.rsx
正常出力: c:\tekito\sample.rsx.csvEXCELを起動し、「データ>データの取得と変換>テキストまたはCSVから」で出力されたファイルを選択すると、こんな感じで読み込むことができました!
ドキュメントから抽出したテキストデータのCSV(クリックで拡大)
最後に
ここではDOMでRSXを読み込みテキストデータもメモリ上に溜め込む富豪的なやり方で抽出を行いましたが、メモリが限られている環境やサイズの大きいドキュメントを読み込む必要がある場合は逐次処理をしてリソースを節約する必要があると思います。