Java17でUnicode拡張書記素クラスタを扱うなら正規表現を使うのが手軽で良さそうです
製品開発担当の大です。こんにちは。
Javaの3年ぶりのLTSであるJava17がリリースされて2ヶ月経ちました。現在エイチ・オー・エスでは弊社Java関連製品のJava17での検証作業を行っております。申し訳ありませんが今しばらくお待ちください。
さて、今日はUnicode拡張書記素クラスタ(Unicode Extended Grapheme Cluster)のお話です。
Unicode拡張書記素クラスタ(Unicode Extended Grapheme Cluster)
Unicode拡張書記素クラスタというのは簡単に言うと「ユーザが認識できる単一の文字」のことです。複数のUnicodeコードポイントで構成される場合があります。詳しくは下記のサイトをご覧ください。
正規表現
JavaではJava9から正規表現に任意のUnicode拡張書記素クラスタにマッチする「\X」とUnicode拡張書記素クラスタ境界にマッチする「\b{g}」が導入されました。
当然Java8以前では使えませんので例外(java.util.regex.PatternSyntaxException)になります。Java9以降でもLTSでないJavaはすでにサポートが終わっていますので、実質使えるのはJava11とJava17だけですね。
使ってみる
以下のような表示上は20個の文字をひとつの文字列に入れ、書記素クラスタで分割してカウント・表示してみます。(HTMLでの表示はお使いのOS・ブラウザやフォント等環境に依存します)
| HTMLでの表示 | コードポイント | 備考 | |
|---|---|---|---|
| Grapheme clusters (both legacy and extended) | |||
| 00 | g̈ | U+67 U+308 | ダイエレシス付きのラテン小文字G (Combining Character Sequences) |
| 01 | 각 | U+1100 U+1161 U+11A8 | 각、ハングル音節GAG(Sequence of conjoining jamos) |
| Extended Grapheme Clusters | |||
| 02 | நி | U+0BA8 U+0BBF | タミル語 ni |
| JIS X 0213 | |||
| 03 | セ゚ | U+30BB U+309A | アイヌ語仮名 |
| Standardized Variation Sequence | |||
| 04 | 0︀ | U+30 U+FE00 | 0̸、斜線付きゼロ |
| 05 | ᠠ᠋ | U+1820 U+180B | モンゴル文字 A、second form; isolate medial final |
| Ideographic Variation Sequence | |||
| 06 | 辺󠄂 | U+8FBA U+E0102 | 辺の異体字 |
| Emoji | |||
| 07 | 😃 | U+1F603 | [Emoji 1.0] 大きい目の笑顔 |
| 08 | 🇯🇵 | U+1F1EF U+1F1F5 | [Emoji 1.0] 日本の国旗(Flag Sequence) |
| 09 | ☝🏿 | U+261D U+1F3FF | [Emoji 2.0] 上を指差す手: 濃い肌色 (modifier sequence) |
| 10 | 👨👩👦👦 | U+1F468 U+200D U+1F469 U+200D U+1F466 U+200D U+1F466 | [Emoji 2.0] 家族: 父母と男の子2人 (ZWJ sequence) |
| 11 | 1️⃣ | U+31 U+FE0F U+20E3 | [Emoji 3.0] 囲み数字: 1 (keycap sequence) |
| 12 | 👩✈️ | U+1F469 U+200D U+2708 U+FE0F | [Emoji 4.0] 女性パイロット |
| 13 | 🏴 | U+1F3F4 U+E0067 U+E0062 U+E0065 U+E006E U+E0067 U+E007F | [Emoji 5.0] イングランド国旗 (tag sequence) |
| 14 | 👩🏽🦱 | U+1F469 U+1F3FD U+200D U+1F9B1 | [Emoji 11.0] カーリーヘアの女性: 中くらいの肌色 |
| 15 | 👨🏾🦼 | U+1F468 U+1F3FE U+200D U+1F9BC | [Emoji 12.0] 電動車椅子に乗る男性: やや濃い肌色 |
| 16 | 🧑💼 | U+1F9D1 U+200D U+1F4BC | [Emoji 12.1] オフィスワーカー |
| 17 | 👨🍼 | U+1F468 U+200D U+1F37C | [Emoji 13.0] 授乳する男性 |
| 18 | 🧑🏻❤️💋🧑🏼 | U+1F9D1 U+1F3FB U+200D U+2764 U+FE0F U+200D U+1F48B U+200D U+1F9D1 U+1F3FC | [Emoji 13.1] キス: 明るい肌色, やや明るい肌色 |
| 19 | 🫃🏼 | U+1FAC3 U+1F3FC | [Emoji 14.0] 妊娠する男性: やや明るい肌色 |
private static final int [] CODE_POINTS = {
// [00]
0x67, 0x308,
// [01]
0x1100, 0x1161, 0x11A8,
// [02]
0x0BA8, 0x0BBF,
// [03]
0x30BB, 0x309A,
// [04]
0x30, 0xFE00,
// [05]
0x1820, 0x180B,
// [06]
0x8FBA, 0xE0102,
// [07]
0x1F603,
// [08]
0x1F1EF, 0x1F1F5,
// [09]
0x261D, 0x1F3FF,
// [10]
0x1F468, 0x200D, 0x1F469, 0x200D, 0x1F466, 0x200D, 0x1F466,
// [11]
0x31, 0xFE0F, 0x20E3,
// [12]
0x1F469, 0x200D, 0x2708, 0xFE0F,
// [13]
0x1F3F4, 0xE0067, 0xE0062, 0xE0065, 0xE006E, 0xE0067, 0xE007F,
// [14]
0x1F469, 0x1F3FD, 0x200D, 0x1F9B1,
// [15]
0x1F468, 0x1F3FE, 0x200D, 0x1F9BC,
// [16]
0x1F9D1, 0x200D, 0x1F4BC,
// [17]
0x1F468, 0x200D, 0x1F37C,
// [18]
0x1F9D1, 0x1F3FB, 0x200D, 0x2764, 0xFE0F, 0x200D, 0x1F48B, 0x200D, 0x1F9D1, 0x1F3FC,
// [19]
0x1FAC3, 0x1F3FC,
};
private static final String DATA = new String(CODE_POINTS, 0, CODE_POINTS.length);
private int index = 0;
private void showGraphemeCluster(String data) {
String s = data.codePoints()
.mapToObj(i -> String.format("0x%X", i))
.collect(Collectors.joining(",", "[", "]"));
System.out.printf("[%02d] %s -> %s\n", index++, data, s);
}
「\X」を使う場合
Matcher matcher = Pattern.compile("\\X").matcher(DATA);
int count = 0;
while (matcher.find()) {
showGraphemeCluster(matcher.group(0));
count++;
}
System.out.println("count: " + count);
「\b{g}」を使う場合
long count = Pattern.compile("\\b{g}")
.splitAsStream(DATA)
.peek(this::showGraphemeCluster)
.count();
System.out.println("count: " + count);
Java17で実行してみます。
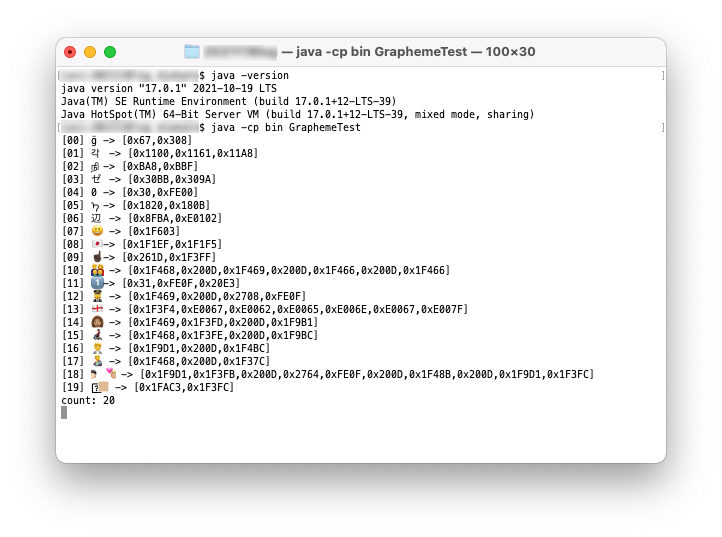
Java17の実行結果
表示は一部おかしいですが、どちらの場合も正しく分割されました。Emoji13.1以降の絵文字の表示についてはこのブログを書いている時点で環境側の対応がまだっぽいですね(macOS Montereyで試しました)。そのうちちゃんと表示されるようになるでしょう。
これをJava11で実行してみます。
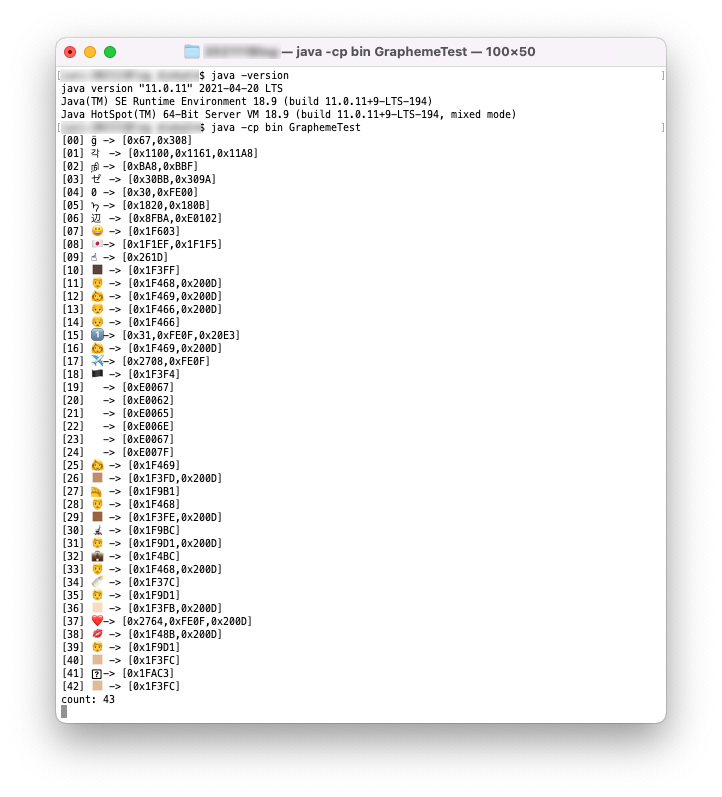
Java11の実行結果
今度は変な感じで分割されました。Emoji 2.0のmodifier sequence、ZWJ sequenceあたりからおかしくなってますね。ちなみにJava17はUnicode13.0に対応しており、Unicode13.0のEmojiのバージョンは13.0です。Java11はUnicode10.0に対応しており、Unicode10.0のEmojiのバージョンは5.0なのでそのあたりまでは正確に分割できて欲しいところですが、この結果を見るとJava11時点ではEmoji対応はまだ不十分だったように見えます。
Java11以前ならICU4JのBreakIteratorを使う
Java11以前なら、もし使える環境にあるならICU4JのBreakIteratorを使うのが良さそうです。
BreakIterator it = BreakIterator.getCharacterInstance();
it.setText(DATA);
int count = 0;
int prev = 0;
while (it.next() != BreakIterator.DONE) {
count++;
showGraphemeCluster(data.substring(prev, it.current()));
prev = it.current();
}
System.out.println("count: " + count);
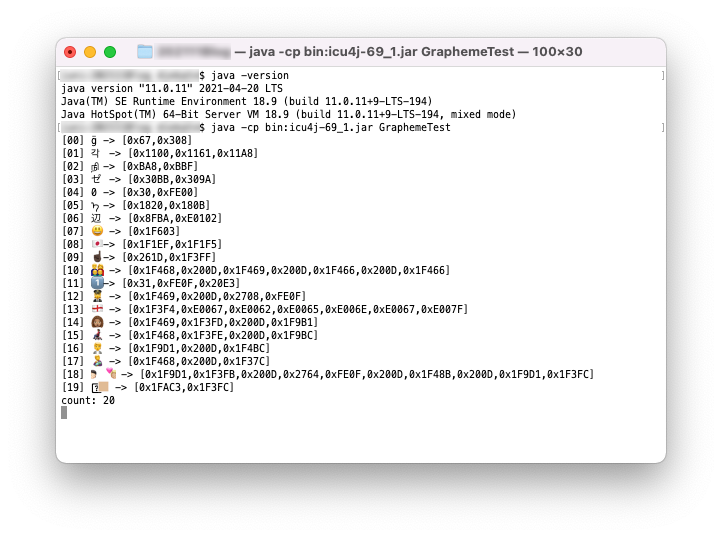
ICU4Jの実行結果
Java11でも正しく分割されましたね!ちなみにJava17でもJava8でも大丈夫です!
止むを得ずjava.text.BreakIteratorを使う
Java11以前で、ICU4JのBreakIteratorが使えない環境なら、不十分であることを割り切ってJava標準のBreakIteratorを使います。使い方はICU4JのBreakIteratorと同じです(ネームスペースがcom.ibm.icu.textからjava.textに変わるだけ)
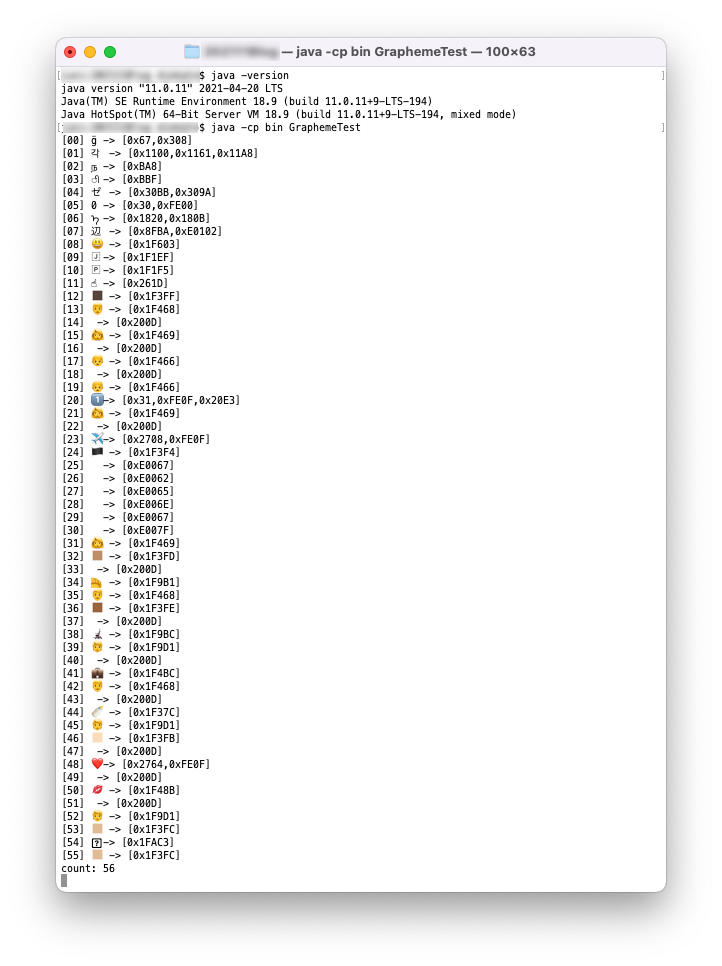
java.text.BreakIteratorの実行結果
だいぶ怪しいですが一応分割できてるところもある。。。かな。
2023/8/28 追記
Java20以降はjava.text.BreakIteratorもUnicode拡張書記素クラスタに対応しました。
⇨ java.text.BreakIteratorがUnicode拡張書記素クラスタに対応した


